Generative adversial networks also called GANs are used to generate images by taking a random-uniform noise as an input. The networks consists of two main parts:
- Generator -> Takes the noise as input and generates images
- Discriminator -> Guesses if the image is generated by generator or if the image came from the training data.
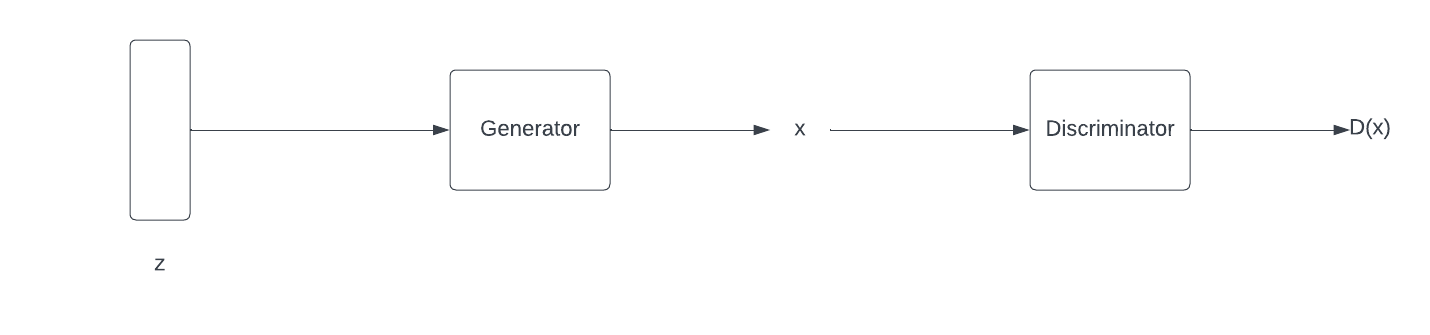
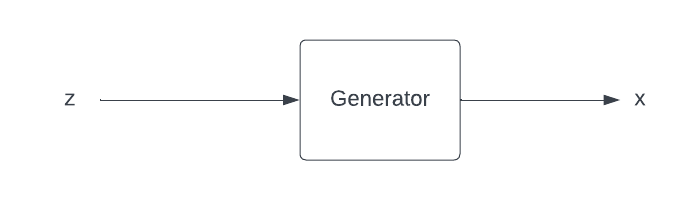
Generator
The generator takes a random uniform noise($z$) also called latent vector, as input and outputs an image, let’s say $x$. The intuition I have is, the generator estimates the distribution of the training dataset which is used to train the discriminator. As the training goes the generator generates images more similar to the training set. This makes it hard for the discriminator to detect if the images generated by the generator are real(images from training data) or fake(images generated by the generator).
Now for the generator to improve in generating images similar to the training dataset it needs to learn. The learning is possible because of discriminator, without it the generator produces nothing but noise. The generator learns or estimates the training distribution by backpropagating. With change in parameters due to back-propagation the generator gains information and becomes good at generating real-like images.
We can describe the generator as some function $ G $ which estimates the distribution and generates an image $ x $ by taking $ z $ as input.
$$x = G(z)$$
- x -> Image
- G -> Generator function
- z -> latent vector or random noise
Discriminator
The discriminator takes an image generated by the generator as an input and outputs a probability($D(x)$) that $x$ is real. The generator is trained on both real and fake images. The main goal of discriminator is to identify the fake images. As the training goes the generator becomes good at producing images very similar to the training set. This makes it difficult for the discriminator to guess if it is a fake or real image, the probability then is random, there is 50% chance that the image is either real or fake. And that is when we stop training.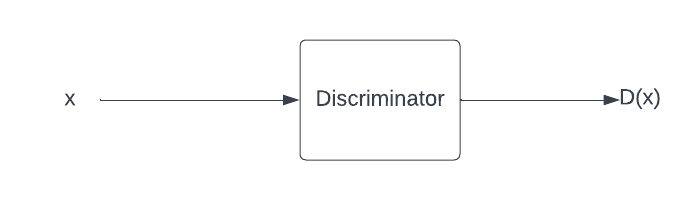
DCGAN
DCGAN is a fully convolutional network, it doesn’t use max pooling or any fully connected layers.
- Generator:
- Input: takes a 100 dimensional latent vector
- Output: Generates an image(64 x 64 x 3 dimensions)
- Layers: Uses transpose convolutions, Batch Norm, ReLu except the last layer which uses tanh activation function
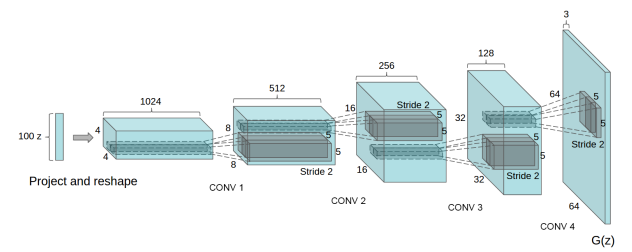
DCGAN generator, image taken from the ‘UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS’ paper
- Discriminator:
- Input: Takes either real or generated image as input, dimensions: 64 x 64 x 3
- Output: Gives a probability that the given image is real
- Layers: Uses strided convolutions, Batch Norm, Leaky ReLU
Project: DCGAN on anime face dataset
In this project DCGAN is used to generate anime faces. The discriminator is trained on anime face dataset. Binary cross entropy is the loss used for this project.This project was deployed locally using python flask.
Sample images from training set:
Generator code
#generator code
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
#input is z
nn.ConvTranspose2d(z, ngf*8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf*8),
nn.ReLU(True),
nn.ConvTranspose2d(ngf*8, ngf*4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf*4),
nn.ReLU(True),
nn.ConvTranspose2d(ngf*4, ngf*2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf*2),
nn.ReLU(True),
nn.ConvTranspose2d(ngf*2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
Discriminator code
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf, ndf*2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf*2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf*2, ndf*4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf*4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf*4, ndf*8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf*8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf*8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
DCGAN is trained for 100 epochs. The plot of generator and discriminator losses: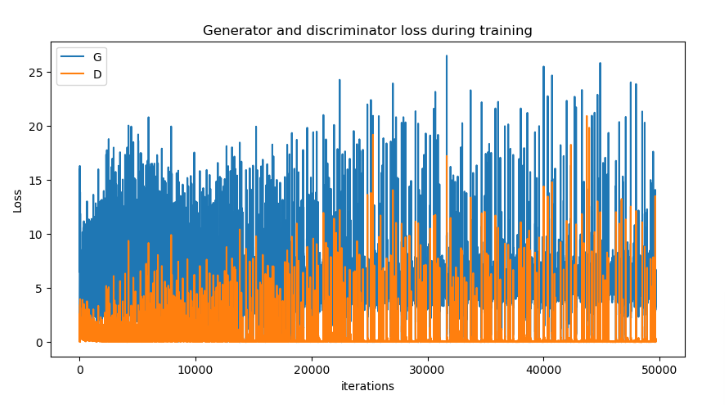
The images generated by the generator were saved and these are few images generated by the generator during last epoch:
A screenshot of the webpage deployed locally:
💡Improvements
- The above generated image is made larger to 512px using CSS so there isn’t much clarity in the generated image. DCGAN generates an image of size 64 x 64 x 3, to produce an image larger than that we need to change the architecture of the model. To generate larger images we can change the layers of generator and discriminator to grow progressively(Progressive growing GANs).
- A more faraway approach could be to not use the noise directly but introduce mapping layer which is implemented in StyleGAN.
References and links
Links to repo and code
More details on the implementation can be found here! Link to kaggle notebook can be found here!
References
[1] Goodfellow, Ian, et al. “Generative adversarial networks.” Communications of the ACM 63.11 (2020): 139-144.
[2] Radford, Alec, Luke Metz, and Soumith Chintala. “Unsupervised representation learning with deep convolutional generative adversarial networks.” arXiv preprint arXiv:1511.06434 (2015).
[4] https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html